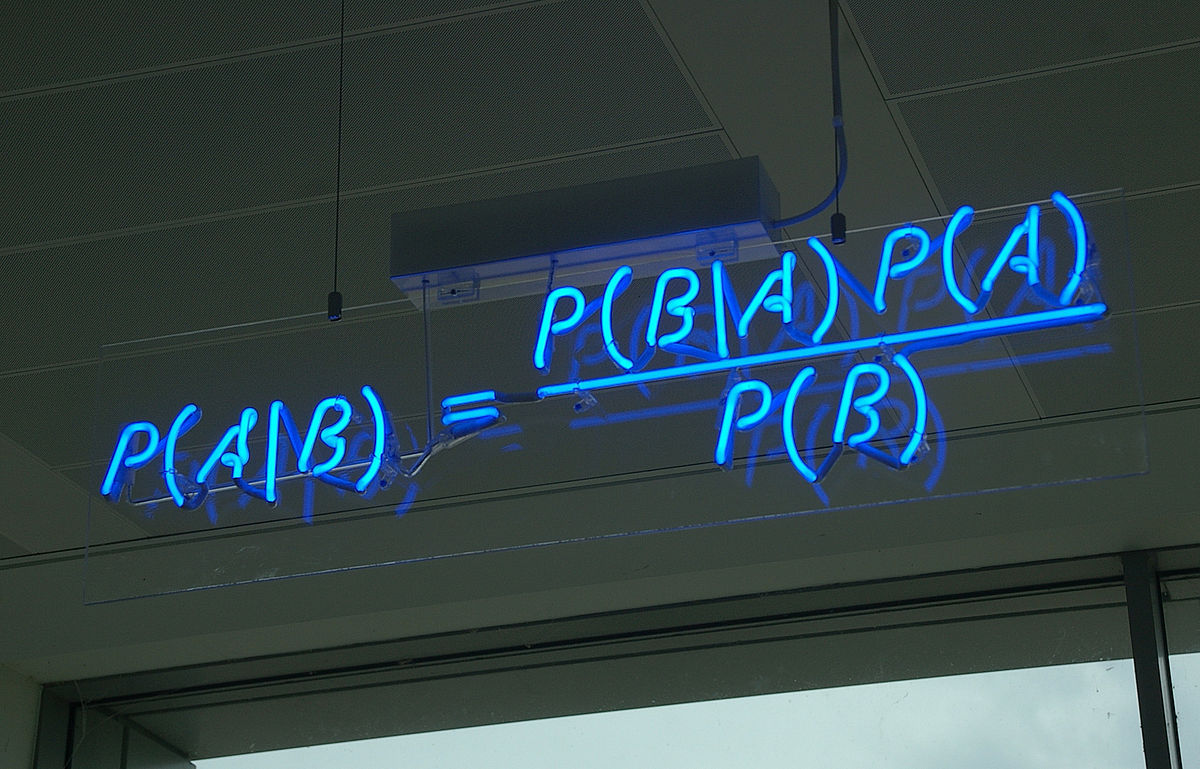

I took a break from playing Animal Crossing (albeit a short one) so that I could play with the new update to Super Mario Maker 2 (SMM2); the addition of SMB2, and its world creator. I’ve been looking for a new “short-ish” type project to work on while I take a break from other projects, and I wondered whether I could use some form of machine learning to generate levels for SMM2. Also, there’s always more room for learning, and this gave me an opportunity to re-brush up on RNNs (not having used them since I graduated), and work with VAEs.
There are some really awesome levels and I wanted to see if a “sticks and stones” ML model could do any better. Be warned that this method is guaranteed to take much longer than building a level manually. My ultimate goal is to create a “Kaizo” level.
For those who aren’t pro-gamers (like me), SMM2 is essentially an “infinite” Mario game. It has a story line, but its main draw is that players can create their very own levels, in many different styles of the game, using every possible element of the original games and more. This means there’s a lot of factors, features, and other variables to consider, especially across the different game styles; different {enemy, block, power-up, item, building} types. To make this project easier and less time consuming (also constraining it a little), I decided to focus solely on the SMW game style within SMM2.
My intention is to build a simple baseline model to generate levels, followed by a RNN \(\pm\) LSTM, and a VAE. Initially, I was going to dive straight into VAEs, as I’ve recently been studying them, however as I got more familiar with the problem and figured this would be a sequential text-based problem I’d be working on, that I’d first start with simple language models (LMs).
I’ve broken this post into a series as I anticipate it will otherwise be way too long to fit into one post. This first post, aptly named World 1-1, will focus on introduction, data collection/exploration, feature engineering, and building n-gram and Markov Chain LMs.
Also, some “preface” notes; 1) this is just a project worked on solely for a bit of fun and to learn stuff along the way. I have no real interest in PCG, meaning I didn’t spend too long researching the field, except skimming some papers, and so I probably am not making use of existing algorithms and/or methods present in PCG meaning some of my assumptions or paths are likely to be wrong; and 2) because these posts have the potential to be very long, I won’t be explaining things like how a RNN works in detail, instead I’ll assume the reader has some familiarity with the topics presented. The references section at the bottom of the page will contain a bibliography of papers + extra learning & reading materials.
Contents
World 1-1: An Introduction
What is a Kaizo level?
“Kaizo Mario” is a ROM hack of Super Mario World which was created by a Japanese ROM hacker [1]. If you’re unfamiliar with these terms, people used to, and still do, hack Mario ROMs (Nintendo read-only-memory chips stored in the old GBA cartridges which contain game data) to either mod the game or create new content. In this case, it’s to create new levels. The Kaizo ROM hack was very difficult, requiring very precise and fast reactions, while using elements of the game originally not intended for such things (such as throwing a shell against a wall in mid-air and using it to reach a higher place – shell jumps). Since then, Kaizo has referred to Mario levels which are extremely difficult, but fun, and require many complex aspects of the game mechanics to be mastered.
SMB1
Ah, Super Mario Bros. ![]()
Admittedly, my favourite (Mario) game is SMB2, but SMB being the classic that it is means it kinda has to be the center of attention. Even though my aim with this project is to generate levels for SMM2, I decided to start at the true beginning. I’m going to build all my models from start to finish using levels only from SMB. Also, a key factor is that the data is easier to acquire :-). Once the models are built and work (whatever that may mean), I’ll swap out the dataset for one from SMM2 containing SMW kaizo levels. My assumptions and other feature engineering may break or fall apart, or at the very least suffer some type of loss, but that’s ok. I’ll fix that when I get there if needed.
SMB levels are contained in The Video Game Level Corpus [2] dataset. The (VGLC) contains levels for a variety of games in a few different formats, such as images and processed text files. Here’s an example from Super Mario Bros/Processed/mario-1-1.txt:
----------------------Q-------------------------------------------- ------------------------------------------------------------------- ------------------------------------------------------------------- ----------------------------------------------------------------S-- ----------------Q---S?SQS---------------------<>---------<>-------- --------------------------------------<>------[]---------[]-------- ----------------------------<>--------[]------[]---------[]-------- ---------------------E------[]--------[]-E----[]-----E-E-[]-------- XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
I’ve removed some sections of the sky just to keep it looking nice in this post. Can you remember this part of the level? 😉
SMB1 levels are made up of only a few items/objects (17-14~). We can use the .json provided by the VGLC to map a character in the processed level file to an in-game item or object like so:
Each item also has properties, such as solid, passable, empty, damaging, etc, which aren’t directly represented in the text file. However, the format is nice and easy to read and interpret which is helpful in modelling. Another thing to note is that Mario levels in SMB are constrained to being between 150×14 and 374×14 in size.
SMM2
Unfortunately, unlike the neatly organized and well maintained VGLC dataset where we can grab levels from SMB, there exists no such thing for modern console games, SMM2 included. This doesn’t mean it’s impossible though…
Thanks to some great reverse engineering going on in the homebrew Switch community, there’s been nice progress on extracting data from many of the games on the Switch giving rise to data mining, modding, and more. Specifically, I make use of the work on decrypting SMM2 levels and the documentation on the level file format.
For this project, I made use of 0Liam’s compilation of SMM2 file format documentation and simontime’s SMM2 course decryptor. This, in conjunction with a website that has user submitted levels from SMM2 available to download meant I could feed the models SMM2 kaizo levels. Even so, building a dataset for SMM2 isn’t as straightforward as download + decrypt, since there’s a lot of pre-processing work required, including generating a text based representation of the level and encoding all the objects and items. More on this later.
Level Processing – SMB1
Now that I have the text representations of the levels from SMB1, it’s time to process them as input. If you look at the design of Mario levels, you’re usually able to see patterns column-wise throughout the level, rather than horizontally/row-wise. Our data is a text file, which is technically read in row-wise manner, i.e, 1 line at a time. If you take another look at the section of the level I showed above, examining the first line ... ---Q------ ... is incredibly boring and tells us almost nothing about the level nor about any possible relationships between objects. Actually, let me re-word that. The only information we can extrapolate from this is that in 67 characters, 66 of them are sky “blocks” and 1 is an empty question block. How fun.
So while there is info in the above data, it’s looking quite sparse, and almost useless when we’ll be dealing with probabilities and content generation. If we were to process this file as-is, and learn from it, there would be very little relationships present between any objects. Also, we could (depending on the model and blah, blah, blah…) lose relationships from the previous row, meaning that our final level might have things like question blocks in impossible to reach places, as we might never generate enough blocks that can reach it from underneath.
Therefore, to process the levels, I decided to basically “transpose” the text file, meaning we’ll be reading the level column-wise which should allow for stronger relationships column-to-column.
"""
# return generator with file names
def get_level_files(data_dir: str) -> Generator:
level_files = (f for f in os.listdir(data_dir) if os.path.isfile(os.path.join(data_dir, f)))
return level_files
"""
# return list of file names
def get_level_files(data_dir: str) -> list:
level_files = [f for f in os.listdir(data_dir) if os.path.isfile(os.path.join(data_dir, f))]
return level_files
def init_process_levels(data_dir: str):
if not os.path.exists(data_dir + "col_levels/"):
os.makedirs(data_dir + "col_levels/")
level_files = get_level_files(data_dir)
for lf in level_files:
tmp = []
with open(data_dir + lf, "r") as f:
for line in f:
tmp.append(line.rstrip())
# "transpose" the level
tmp = zip(*tmp)
level = []
for col in list(tmp):
level.append("".join(col))
with open(f"{data_dir}col_levels/{lf}", "w") as f:
for col in level:
f.write(f"{col}\n")
data_dir = "data/smb/Processed/"
init_process_levels(data_dir)
def read_level(data_dir: str, level_name: str) -> list:
level = []
with open(data_dir + level_name) as f:
for line in f:
level.append(line.rstrip())
return level
level = read_level(data_dir + "col_levels/", "mario-1-1.txt")
The code is pretty straight-forward, but the key part is line tmp = zip(*tmp). What’s happening here is we first unpack our level list which would look something like [str(row_1), str(row_2), ...], using the star operator, *. This returns the list as positional arguments which are then passed to zip. If you’ve never seen zip, it takes in a bunch of iterables, our strings, and returns them in an aggregated tuple. If that doesn’t make sense, here’s an example:
>>> a = ["aa", "bb", "cc"]
>>> list(zip(*a))
[("a", "b", "c"), ("a", "b", "c")]
For now, this is all the processing we need…
Language Models
N-grams
N-grams will be the first LM used. They are a surprisingly simple and intuitive model/concept in NLP. When referring to an n-gram, I mean a contiguous sequence of \(n\) items from a given sequence of something. In our the case, the something, is text, and the text is our level data. As an example, let’s take the sentence “I love Mario so much. All I do is play Mario on my Nintendo console.”. If we start making n-grams out of this sentence, we end up with the following:
- 1-gram: (“I”), (“love”), (“Mario”), …
- 2-gram: (“I”, “love”), (“love”, “Mario”), (“Mario”, “so”), …
- 3-gram: (“I”, “love”, “Mario”), (“Mario”, “so”, “much.”), (“much.”, “All”, “I”), …
If we generalize this, we can say that given a sentence \(S\), and an integer \(n\), we construct a list of words that occur next to each other, until we’ve exhausted the corpus. What remains is a list of n-grams. From here, we can begin counting the occurrences of each n-gram and assigning frequencies to them which allows us to do certain tasks.
This model allows us to do things like predicting the next word in a sequence, the likelihood of a sentence occurring, auto-correct or “predictive” text similar to the ones on smartphones (obviously much less accurate), or even generate new text. The latter is what I’ll be focusing on, and as long as you understand joint probabilities, you’ve already understood almost all n-gram modelling.
As an example, with a bigram, the task of computing \(P(w|h)\), the probability of a word \(w\) occurring, given some history \(h\) is as follows:
\(P(\text{Mario}|\text{love}) = \frac{P(\text{love Mario})}{P(\text{love})}\)
This is read as, the probability of “Mario” appearing after “love” is the number of times that “love Mario” appears in our corpus, divided by the number of times “love” appears. Try and work this out yourself.
Similarly, with a trigram, this becomes:
\(P(\text{so}|\text{love Mario}) = \frac{P(\text{love Mario so})}{P(\text{love Mario})}\)
And calculating the probabilities with a unigram model consists of simply counting the occurrences of a word and dividing it by the total words in the corpus.
This method of estimating probabilities will differ based on our \(n\) value from when we computed the n-grams. A higher value like 3 will give us more accurate results than a value of 1 as we have more history to look at. However, this begins to get more complicated as \(n\) grows as we’ll need to do larger and longer divisions. Here is where the chain rule of conditional probability comes in. We can use it to compute probabilities of sequences such as \(P(w_1, w_2, …, w_{20})\):
\(P(w_1…w_{n}) = P(w_1)P(w_2|w_1)P(w_3|w_1^2) … P(w_n|w_1^{n – 1}) = \large{\Pi}_{k=1}^n P(x_k|x_1^{k-1})\)
Level generation
To generate a level, we first give our LM a starting word, or in this case, a starting column(s)/level slice(s). As we have the n-gram frequencies throughout our corpus, one way of generating new levels would be to take a weighted random sample from our distribution based on the current column, and feed that back in as input. We repeat this process until we say stop or a limit is reached.
And here’s an example of what the above n-gram LM can produce:

Generated level as text 
Generated level being played
Pretty cool right? It’s even playable! [3] The level we’ve generated is definitely very simple and not that exciting, but it sticks to the Mario theme and is feasible. Can we improve it? Yes, obviously, look at the post title…
Markov Chains
Generating new levels like we’ve done above is certainly valid, but to formalize this a little more, Markov chains [4] are employed, which make use of the Markov process and are a better probabilistic model.
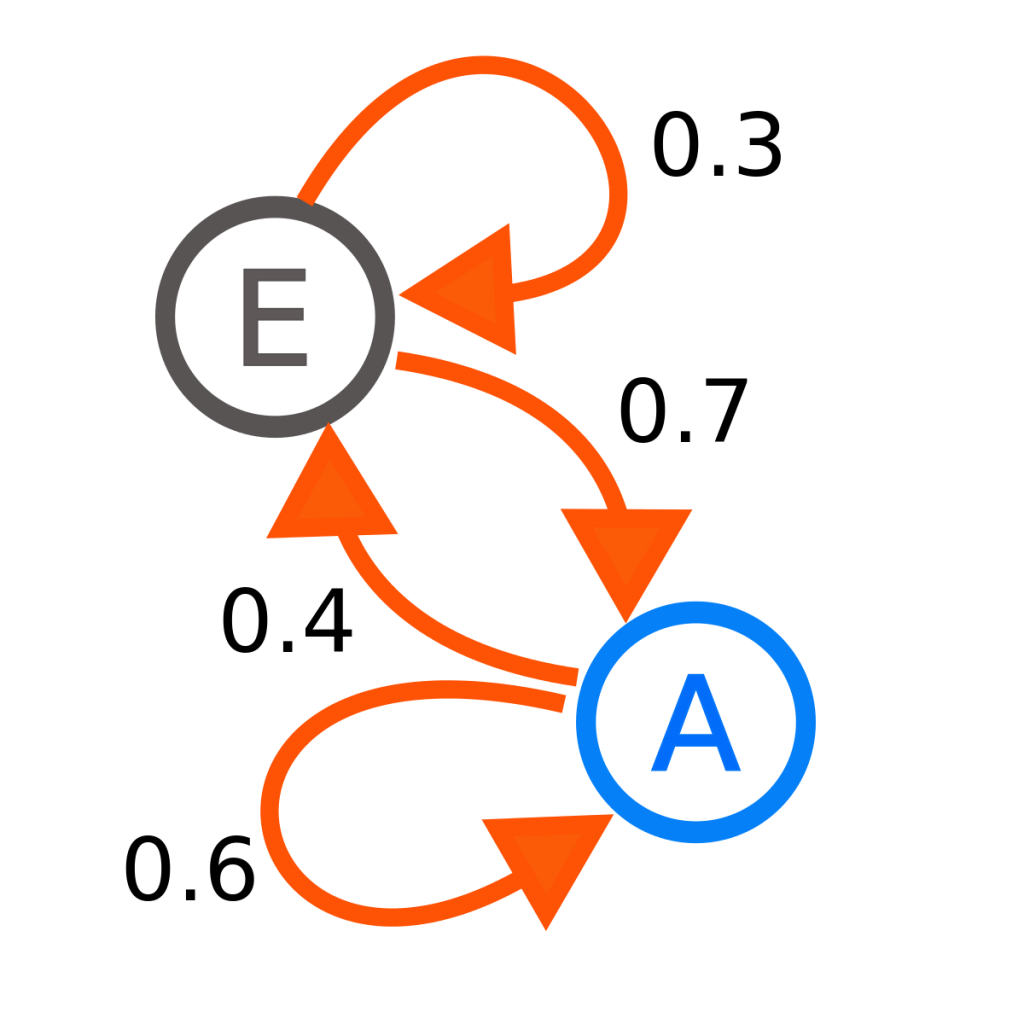
A Markov process is a stochastic process which satisfies the Markov property. This means the conditional probability distribution of the future states of our stochastic process must depend only on the present state. In other words, the process forgets all previous history and is only conditioned on the current state.
A Markov chains is a type of Markov process, but not “strictly”. Because Markov chains can really be defined as having discrete time in continuous space, that continuous space is not defined in the Markov process. Similarly though, Markov chains can also be defined as having a countable state space. This is a great intuitive example of how a Markov chain works.
We can use the concept of Markov chains and n-grams to build a LM for the level generator. Markov chains can be of different orders, which essentially represents the “history” of states it can look at, which again, makes it a little iffy when talking strict Markov processes. Increasing the order of a chain can make it grow exponentially, so it’s important to keep it low, unless you don’t care about space complexity then go crazy.
For the level generator, I’ll be using a 2nd order Markov chain, which you can look at as similar to a trigram. So rather than predicting the next level slice based only the present one, we’ll also be looking at \(w – 1, w – 2\). Using the probability model presented in the n-gram section, we’re essentially approximating with:
\(P(w_n|w_{n – 1}, w_{n – 2})\)
class MarkovChain():
def __init__(self):
self.markov_chain = dict()
def _transition(self, key: tuple, value: str):
"""
internal function, generates markov chain transitions
"""
if key not in self.markov_chain:
self.markov_chain[key] = []
self.markov_chain[key].append(value)
def chain(self, cols: list, n: int):
"""
cols: list of all possible states in the markov chain (i.e, unique cols in the level)
n: markov chain order
"""
ngrams = list(zip(*[cols[i:] for i in range(n)]))
for ngram in ngrams:
self._transition(ngram[:n - 1], ngram[-1])
def generate_level(self, curr_col: tuple, n: int = 10) -> list:
"""
curr_col: tuple of starting level columns
n: how many new cols to generate
"""
new_level = list()
new_level.extend(curr_col)
for i in range(n):
next_col = self.markov_chain.get(curr_col)
next_col = random.sample(next_col, 1)[0]
new_level.append(next_col)
curr_col = (curr_col[1], next_col)
return new_level
m = MarkovChain()
m.chain(level, 3)
m_level = m.generate_level((('-------------X', '-------------X')), 100) # smb1
When we generate the Markov chain, m.chain(level, 3), we can inspect it directly with m.markov_chain:
{
('-------------X', '-------------X'): ['-------------X', '-------------X', '-------------X', '-------------X', ... , '---------Q---X', ...],
('-------------X', '---------Q---X'): ['-------------X', '-------------X'],
('---------S---X', '---------?--EX'): ['-----Q---S---X'],
...
}
You can see here that when we have ('-------------X', '-------------X') there are a lot of next states we can go to in our chain, but when we’re at ('-------------X', '---------Q---X') there’s only two possible next states. Note I’ve also cut out a lot of -------------X from the first state, since plain ground almost always follows plain ground.
Level Generation
To generate a new level, we use our current state, and look at the chain for which possible next states we can go to. We then randomly sample until we’re happy with the result or reach a desired level length. Since I sampled a level of length 100 it’s too long to paste as text, so here it is in action (me playing… the A* algorithm in the Mario AI framework couldn’t figure out how to beat the level):

Level Processing – SMM2
Ok so, initially, I said that only once all the models were trained was I going to use a dataset built from SMM2 kaizo levels. Well, that was a lie. Because the results I’d got thus far were actually “not too bad™”, and I was feeling inpatient, I decided to go on ahead and build a dataset for SMM2. So here we are, back at level processing! This time, things get a lot more complicated.
The pipeline here is more involved and tedious than the previous level processing, so here’s what I did without going through everything:
- Download SMM2 encrypted kaizo levels
- Decrypt levels
- Manually play around (for hours) with a decrypted level while going through the level format specifications
- Agree what data needs to be extracted from the level
- Write some code to generate a textual representation of the level, column wise
- Scrape all kaizo levels and generate a huge dataset based on the above steps. I ended up writing a chunky, but neat, Bash script for this
The GitHub repo for this section is here. It has some information regarding the top 2 bullet points. I won’t talk about the 3rd since that was very time consuming and everything I learned from it is present in #4. Therefore I’ll be discussing solely bullet points 4 and 5.
To decide what data needed to be extracted I used the information present in object_information.md, alongside how SMB1 levels were represented. The object information table shows the objects ID, extracted from the file, the object name, category, width, and height. The VGLC processed text files map each object to a specific character. If we do that here then we’d need 119 single width characters… which turns ugly. Instead, I decided to focus on growing the number of categories and mapping each item in the text file to the first letter of the category name. So as an example, if an enemy is present, it would be represented as the letter E in the file. This is close to the original file format while growing our feature size.
In addition to this I deemed it was important to add the following new categories: \(\{?, 0, B, C, D, E, G, I, L, M, N, P, S, T, U, W\} \rightarrow \{\)question mark block, Mario, belt, coin, door, enemy, gizmo, item, Lakitu (different enemy), moving, none, pipe, switch, terrain, power up, win\(\}\).
- Lakitus are not in the
enemycategory because they’re so different and much more annoying than regular enemies I thought it might be interesting to see where a trained model might place them movingconsists of things like Thwompsbeltandpipeare crucial gameplay elements but also have respective width and height, therefore need extra attentiondoorlets Mario go between areas which is important to keep track ofpower upmay add interesting dynamics or allow for areas where the player has to take damage in order to get through an obstacle
Now that these rules have been decided on, it’s just a matter of reading in a decrypted level and generating a processed text based, column-wise, level! Easier said than done of course. I won’t show all of the code in this post since it’s too long, and because it’s on GitHub, but I will go through some of the core functions. I’ve also omitted code comments (of which there are a lot) so for more information, please refer to the repo.
def _init_data(self) -> list:
file_info = list()
obj_info = dict()
with open("object_info.dat") as f:
for line in f:
line = line.split()
obj_info[line[0]] = line[1]
file_info.append(obj_info)
goal_y_pos = self.course[0x1]
goal_x_pos = self.course[0x2]
file_info.append(goal_x_pos)
file_info.append(goal_y_pos)
course_header = self.course[:0x200]
level_style = _decode(course_header[0xF1:0xF1 + 0x3])
if level_style != "MW":
raise Exception("game style needs to be Super Mario World!")
exit()
level_title = _decode(course_header[0xF4:0xF4 + 0x42])
print(f"getting level data from... '{level_title}'")
return file_info
def _get_object_data(object_data: bytes, obj_count: int) -> dict:
objects_info = dict()
for i in range(obj_count):
section_data = object_data[i * 0x20:(i * 0x20) + 0x20]
x_pos = struct.unpack("<I", section_data[:0x4])
x_pos = int((x_pos[0] - 80) / 160)
y_pos = struct.unpack("<I", section_data[0x4:0x8])
y_pos = int((y_pos[0] - 80) / 160)
width = section_data[0xA]
height = section_data[0xB]
raw_flags = struct.unpack("<I", section_data[0xC:0x10])[0]
wings = True if (raw_flags >> 1) & 1 else False
parachute = True if (raw_flags >> 15) & 1 else False
object_type = section_data[0x18:0x1A].hex()[:2]
objects_info[i] = {"x": x_pos, "y": y_pos, "width": width, "height": height,
"raw_flags": raw_flags, "item_properties": (wings, parachute), "obj_type": object_type}
return objects_info
def build_ascii_course(level_data: dict, file_info: list):
print("building ascii course!")
objects_info = level_data["objects"]
tile_info = level_data["tiles"]
#level_mat = np.full((file_info[3] + 1, file_info[4] + 1), "-", dtype = str) # horizontal view
level_mat = np.full((file_info[4] + 1, file_info[3] + 1), "-", dtype = str) # veritcal view
print(f"level is {file_info[4]} by {file_info[3]}")
for k, v in objects_info.items():
object_type = file_info[0][v["obj_type"]][0]
if object_type == "P":
h = v["height"]
# this was fucking mind-bending
if not v["y"] - h < 0:
level_mat[v["y"], v["x"] - 1] = "P"
level_mat[h + 1:v["y"], v["x"]] = "P"
level_mat[h + 1:v["y"], v["x"] - 1] = "P"
#level_mat[v["y"] - h, v["x"]] = ">"
else:
level_mat[v["y"], v["x"] + 1] = "P"
# @TODO
if object_type == "B":
w = v["width"]
level_mat[v["y"], v["x"]:v["x"] + w] = "B"
try:
#level_mat[v["x"], v["y"]] = object_type # horizontal
level_mat[v["y"], v["x"]] = object_type # vertical
except:
if VERBOSE:
print(f"can't place object at {v['x'], v['y']}")
else:
pass
for k, v in tile_info.items():
try:
#level_mat[v["x"], v["y"]] = "X" # horizontal
level_mat[v["y"], v["x"]] = "X" # vertical
except:
if VERBOSE:
print(f"can't place tile at {v['x'], v['y']}")
else:
pass
level_mat = level_mat.T
level_mat[:7, 0] = "X"
if level_mat[7, 1] == "X":
level_mat[:7, 1] = "X"
return level_mat
class Course -> def _init_data():- File header checks including appropriate game style
- Initialize data structures used for later which are important, including mapping object hex values to their respective category
- Note I also generated a new version of object_information.md using
awk -F "|" '{$2 = sprintf("%x", $2)} {print $2, $4}' object_information.md | tail -n +5 | sed 's/\<[0-9|a-f]>/0&/' > object_info.dat
def _get_object_data():- Here we return a dictionary containing all of the levels object data and information stored from \(\text{0x200}\) to \(\text{0x2DEE0}\)
- Each object has a structure of size \(\text{0x20}\) which contains all the information about it
def build_ascii_course():- This is essentially our main function
- We store the level in a
numpymatrix, which I’m not sure is the best way to do it, but it works ¯\_(ツ)_/¯ - Iterate over all the objects and tiles extracted while positioning the corresponding ASCII character in the matrix
- For pipes and belts we need to do some extra mind bending processing to account for their height and width as otherwise a pipe which is 2×8 long may will only take up 1 tile, leaving 15 as empty space – this could negatively affect the generated level representations
- Transpose the matrix to represent the level column-wise
Running this code on a decrypted SMM2 level generates something like this:
XX------XXXXXXXXXXXXXXXXXXX- XX------XXXXXXXXXXXXXXXXXXX- XX----G-------------PPPPPPP- XX------------------PPPPPPP- XX------XXXXXXXXXXXXXXXXXXX- XX---T---XXXXXXXXXXXXXXXXXX- XX-------XXX---------------- XXB-----XXXX---------------- XXB----XXXXX---------------- XXB---XXXXXX----------------
This is the start of a level. Mario falls in through the pipe at the top. In front of him is a belt. The gizmo where he lands is actually an arrow pointing in the direction to go.
Now that the dataset has been compiled and works, it’s time to feed it to the LM’s used and see what we get! Just as a note, because I’ve yet to write something that takes a text-representation of a level and transforms it to an image with actual sprites from the game, this will be a collection of ugly screenshots of text…

Trigram level 1 
Trigram level 2 – unplayable 
Markov chain level 1 
Markov chain level 2

World 1-2…
Awesome, I’ve been able to generate “not too bad™” levels in both SMB1 and SMM2 kaizo! The next post in this “series” will be “World 1-2”, where depending on the length, I’ll write about the RNN and the VAE together, otherwise I’ll have to split it up once more.
Resources & References:
[1] – https://www.romhacking.net/hacks/1887/
[2] – https://github.com/TheVGLC/TheVGLC
[3] – https://github.com/amidos2006/Mario-AI-Framework
[4] – https://en.wikipedia.org/wiki/Markov_chain
Super Mario as a String: Platformer level generation via LSTMs – https://arxiv.org/pdf/1603.00930.pdf
Generating sentences from a continuous space – https://arxiv.org/abs/1511.06349
A Recurrent Latent Variable model for Sequential data – https://arxiv.org/pdf/1506.02216.pdf
Procedural Content Generation via Machine Learning – https://arxiv.org/abs/1702.00539
Evolving Mario levels in the Latent Space of a Deep Convolutional GAN – https://arxiv.org/pdf/1805.00728.pdf
Miscellaneous:
https://www.dartmouth.edu/~chance/teaching_aids/books_articles/probability_book/Chapter11.pdf
https://faculty.sbs.arizona.edu/hammond/archive/ling178-sp06/mathCh8.pdf
http://www.cim.mcgill.ca/~langer/423/lecture14.pdf
https://cw.fel.cvut.cz/b172/_media/courses/bin/markov-chains-2.pdf
https://web.stanford.edu/~jurafsky/slp3/3.pdf
https://www2.stat.duke.edu/courses/Spring12/sta376/lec/mcmctheory.pdf
http://www.cs.columbia.edu/~kathy/NLP/ClassSlides/Class3-ngrams09/ngrams.pdf